Hi, I am a member of technical staff at Project Prometheus.
Academically, I was a postdoctoral researcher at the ETH AI Center, under the supervision of Andreas Krause, Marco Hutter and Bernhard Schoelkopf.
I completed my PhD degree summa cum laude, examined by Georg Martius, Peter Dayan, Mathias Niepert and Matthias Hein, at the Max Planck Institute for Intelligent Systems in Tuebingen, Germany as part of the International Max Planck Research School for Intelligent Systems.
My thesis advisory committee consisted of Georg Martius, Peter Dayan, and Michael Muehlebach, with my primary supervisor being Georg Martius.
In addition, I hold a master's degree in computer science with a machine learning focus from the Karlsruhe Institute of Technology, Germany, and a bachelor's degree in computer science from the University of Zagreb, Croatia.
In 2017 I was fortunate to receive a research fellowship with the Blue Brain Project in Geneva, Switzerland, where I came into contact with neuroscience.
In 2021 I spent some time at Amazon as an applied scientist intern working on variational inference, reinforcement learning and NLP in collaboration with Patrick Ernst and Gyuri Szarvas.
I spent part of 2022 at DeepMind, hosted by Kimberly Stachenfeld in Peter Battaglia's group, working on diffusion generative modelling for building better optimizers in close collaboration with Arnaud Doucet.
In 2024 I was visiting Meta GenAI Zurich, where I worked on building more efficient large-scale diffusion generative models.
Most recently, I was a research scientist at Meta Super Intelligence Labs working on post-training.
My research interests revolve around principled methods for discovery and self-improvement — creating intelligence that can continually adapt and become more efficient in learning and extracting new knowledge. To this end, I have gained rich experience in several sub-areas of machine learning such as reinforcement learning and large generative models, and have led several efforts in academic and industrial settings.
Some of my more recent efforts are centered on post-training for agentic LLMs and distributional optimization in diffusion and flow-matching models.
In my free time I enjoy playing guitar, reading opinionated books on various topics, and all sorts of sports activities.
Feel free to get in touch:
News
Jan 2026Joined Project Prometheus as a member of technical staff.
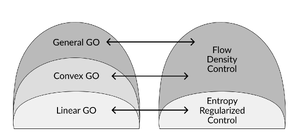
We introduce Flow Density Control (FDC), an algorithm for fine-tuning flow and diffusion models to optimize general utilities beyond average rewards — including risk-averse and novelty-seeking objectives, diversity measures, and experiment design — with priors preserved via divergences beyond KL such as optimal transport distances. FDC reduces this complex problem to a sequence of simpler standard fine-tuning tasks and comes with convergence guarantees via mirror flows. We validate it on text-to-image and molecular design tasks.
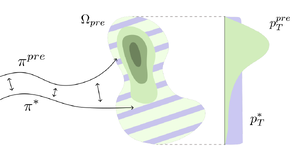
Provable maximum entropy manifold exploration via diffusion models
Controllable distributional manifold exploration.
Riccardo De Santi*, Marin Vlastelica*, Ya-Ping Hsieh, Zebang Shen, Niao He, Andreas Krause ICML 2025, 2025
We provide a principled algorithm for maximum entropy constrained exploration on the distributional manifold induced by a pre-trained diffusion model, with provable guarantees. This enables controllable exploration of the data manifold for applications such as data augmentation, novelty generation, and scientific discovery.
Epistemically-guided forward-backward exploration
Exploration policies that fall out of the forward-backward representation itself.
Zero-shot RL methods like forward-backward representations (FB) have so far been decoupled from the exploration problem. We design exploration policies that arise naturally from the FB representation by minimizing its posterior variance, hence its epistemic uncertainty, and show that this considerably improves sample complexity over other exploration methods.
Offline Diversity Maximization Under Imitation Constraints
Leveraging Fenchel duality for offline skill extraction
Marin Vlastelica, Jin Cheng, Georg Martius, Pavel Kolev RLC 2024, 2024
We propose a principled offline algorithm for unsupervised skill discovery that maximizes diversity while ensuring each learned skill imitates state-only expert demonstrations to a certain degree. Our main analytical contribution connects Fenchel duality, reinforcement learning, and unsupervised skill discovery to maximize a mutual information objective subject to KL-divergence state occupancy constraints. Policies trained on a custom offline quadruped dataset transfer well to the real 12-DoF robot. An earlier version appeared at EWRL 2023 as “Diverse Offline Imitation via Fenchel Duality”.
Learning Diverse Skills for Local Navigation under Multi-constraint Optimality
Quality-diversity trade-off as constrained optimization on a real quadruped.
Jin Cheng, Marin Vlastelica, Pavel Kolev, Chenhao Li, Georg Martius ICRA 2024, 2024
We take a constrained optimization viewpoint on the quality-diversity trade-off and obtain diverse policies by imposing constraints on value functions defined through distinct rewards, with a Van der Waals attract-repel term controlling the diversity level. The learned skills transfer to the real 12-DoF quadruped Solo12 and exhibit diverse agile obstacle-traversal behaviors.
Spuriosity Didn't Kill the Classifier: Using Invariant Predictions to Harness Spurious Features
Spurious features can be safely harnessed at test time — without labels.
Cian Eastwood*, Shashank Singh*, Andrei Liviu Nicolicioiu, Marin Vlastelica, Julius von Kügelgen, Bernhard Schölkopf NeurIPS 2023, 2023
Instead of discarding “spurious” features whose relationship with the label changes across domains, we show they can be safely exploited in the test domain without labels: pseudo-labels from stable features provide sufficient guidance when stable and unstable features are conditionally independent given the label. Our Stable Feature Boosting algorithm learns an asymptotically-optimal predictor without test-domain labels.
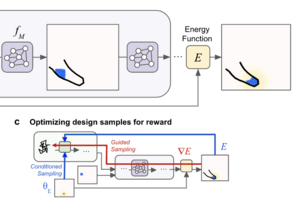
Diffusion Generative Inverse Design
Building better optimizers by guided diffusion
Marin Vlastelica, Tatiana Lopez-Guevara, Kelsey Allen, Peter Battaglia, Arnaud Doucet, Kimberly Stachenfeld ICML workshop on Structured Probabilistic Inference and Generative Modeling, 2023
We propose an improved sampling procedure for a diffusion generative model for approximate sampling from a target distribution that is defined by an energy (cost) function of designs in a complex simulation environment.
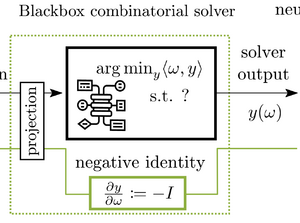
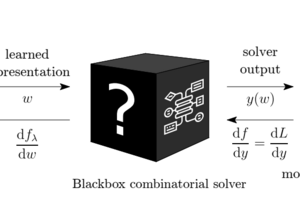
Gradient Backpropagation Through Combinatorial Algorithms: Identity with Projection Works
No need for a solver call on the backward pass (sometimes)
As a continuation of the blackbox-backprop line of work, we introduce a simple modification to the algorith, namely treating the solver as an identity mapping in the computation graph on the backward pass.
This, coupled with projections that avoid degenerate cases, works comparably well as blackbox-backprop.
Taming Continuous Posteriors for Latent Variational Dialogue Policies
Making continuous latents for task-oriented dialogue great again
Marin Vlastelica, Patrick Ernst, Gyuri Szarvas AAAI (oral), 2023
Latent action reinforcement learning for task-oriented dialogue has seen success at benchmarks such as MultiWOZ.
Categorical latents have been argued to be the best choice.
We show that with continuous latents and reformulation of the ELBO objective and the reinforcmenet learning stage, we can achieve state-of-the-art performance on MultiWOZ.
Learning Agile Skills via Adversarial Imitation of Rough Partial Demonstrations
Wasserstein adversarial learning of 'bad' demonstrations
Chenhao Li, Marin Vlastelica, Sebastian Blaes, Jonas Frey, Felix Grimmiger, Georg Martius CoRL (oral, best paper nominee), 2022
In this work we proposed a method for imitating rough demonstrations by a robot quadruped based on Wasserstein adversarial learning of an imitation reward.
We trained a policy via domain randomization and successfully transferred it to the real system, where to robot was able to reproduce agile motions.
Versatile Skill Control via Self-supervised Adversarial Imitation of Unlabeled Mixed Motions
Extracting meaningful behaviors by adversarial learning.
Chenhao Li, Sebastian Blaes, Pavel Kolev, Marin Vlastelica, Jonas Frey, Georg Martius RSS, 2022
Adversarial learning to facilitate unsupervised skill discovery resulting in a controllable skill set by a latent variable with skills that are useful for solving the downstream task.
Risk-Averse Zero-Order Trajectory Optimization
How can we account for uncertainty in zero-order trajectory optimizers?
Marin Vlastelica*, Sebastian Blaes*, Cristina Pinneri, Georg Martius CoRL, 2021
In this work we address the problem of efficient uncertainty estimation in zero-order trajectory optimization via the Cross Entropy Method (CEM).
Moreover, we show that it is essential that we can distinguish between epistemic and aleatoric uncertainty in order to avoid so-called “risky” behaviour.
Neuro-Algorithmic Policies Enable Fast Combinatorial Generalization
As a continuation of the blackbox-differentiation line of work, we propose to use time-dependent shortest-path solvers in order to enhance generalization
capabilities of neural network policies. With imposing a prior on the underlying goal-conditioned MDP structure, we are able to extract well-performing policies through imitation learning that utilize blackbox solvers for receding horizon planning at execution time. Again, this comes with absolutely no sacrifices to the optimality of the solver used.
Differentiation of Blackbox Combinatorial Solvers
Can we embed combinatorial solvers in neural architectures?
Marin Vlastelica*, Anselm Paulus*, Vit Musil, Georg Martius, Michal Rolinek ICLR (spotlight), 2020
Problems that are inherently combinatorial still remain a hinderance for classical deep learning methods.
Traditional methods that try to do gradient propagation through combinatorial solvers rely on sample-based estimates or solver relaxations.
We show that for a specific class of solver, we are able to efficiently compute gradients of an implicit piecewise-linear interpolation of the objective.
This allows us to achieve unprecedented generalization performance on representation learning tasks with combinatorial flavor.
Optimizing Rank-based Metrics via Blackbox Differentiation
Ranking as a blackbox combinatorial problem.
Michal Rolinek*, Vit Musil*, Anselm Paulus, Marin Vlastelica, Claudio Michaelis, Georg Martius CVPR (best paper nominee), 2020
As another continuation of the blackbox differentiation line of work, we show that we can cast the ranking problem as a blackbox solver that satisfies the conditions for efficient gradient calculation, therefore enabling us to optimize rank-based metrics by simply using efficient implementations of sorting algorithms instead of learning a differentiable sort operation. We apply this insight to optimizing mean average precision and recall in object detection and retrieval tasks, where we achieve comparable results to state-of-the-art at the time.
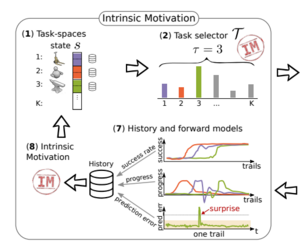
Control What You Can: Intrinsically Motivated Task-Planning Agent
Extracting planning graphs by intrinsic motivation.
Sebastian Blaes, Marin Vlastelica, Jia-Jie Zhu, Georg Martius NeurIPS, 2019
In this work we propose a hierarchical reinforcement learning algorithm that is able to construct planning graphs while managing to use computational resources efficiently,
guided by intrinsic motivation in form of prediction error and measure of task improvement.
Reinforcement Learning with Liquid State Machines
Can we use spiking neural networks for continuous control?
In this work we propose a liquid state machine approach to reinforcement learning of continuous motor control.
The liquid state machine approach with smart spectral radius initialization has shown to extract useful features for motor control which can be used with classical RL algorithms.
KIT at MediaEval 2015-Evaluating Visual Cues for Affective Impact of Movies Task
Evolutionary methods for minimal addition chain exponentiation
In this work we looked at what kind of features we can use for prediction of video valence, violence and sentiment.
Side Projects
FOX (FlOws in JAX)
Normalizing Flows in JAX
Marin Vlastelica
2021
Developing a Python package with standard normalizing flow implementations that is based on JAX and Flax.
Decentralized Energy Exchange
Based on Ethereum blockchain
Marin Vlastelica, Georgi Urumov, Magnus Goedde
2017
As part of hackathon, we have noticed that the future of energy distribution networks are with small producers (via solar cells for example). The missing component is an exchange that makes it possible for producers to exchange energy for value, which we tried to make possible. With this, we have won 1st place on a Microsoft-organized hackathon Germany-wide.